While our search engine covers all sectors we’re often asked what the sector breakdown is. This can be less straightforward to answer that it initially seems because we have a live dataset that is constantly being updated and one that is focused on emerging technology and innovation companies whose businesses often don’t fit into traditional taxonomies. So we decided to investigate the use of topic modelling as a way of answering this question.
Topic modelling provides a means of discovering hidden thematic structure in large collections of texts. A topic model takes a collection of texts as input, in our case company descriptions, and discovers a set of ‘topics’ — recurring themes that are discussed in the collection — and the degree to which each document exhibits those topics. The topics don’t have to be decided in advance, the model itself helps uncover them.
Here is a summary of the topics represented within the VentureRadar data set.
You can hover over the bubbles to see the topic names and the most important keywords associated with each. We found that using 50 topics provided the best balance between being able to represent the wide variety of activities present across the companies whist still being manageable to understand and visualize.
These 50 topics can also be clustered into 6 general themes (try pressing “Split / Group”):
Web/Cloud
Life Sciences/Health
Cleantech/Industry
Fintech
Leisure/Entertainment
Other
We’d like to develop this to become a near real time window into emerging themes in innovation, that changes based on what exists, replacing the old model of trying to fit new companies into old taxonomies.
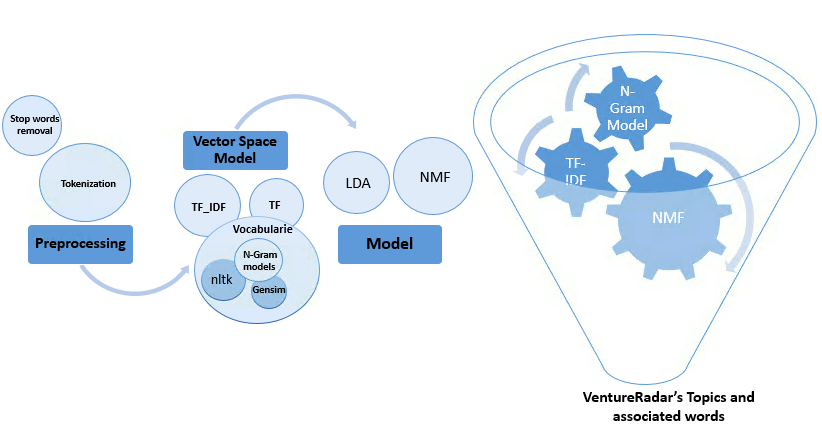
Here’s some more detail on the process; discovering topic models from the VentureRadar data set involved three main steps:
Pre-processing: Removing stop/redundant words and applying tokenization.
Creating Vector Space Model: Create 1-Gram/ 2-Gram models out of the cleaned corpus and create the dictionary.
Building the Topic Model: Pass the built dictionary to the model and create topics from it.